
In any database, including PostgreSQL, it is preferred to use a UNIQUE constraint on a table to avoid the duplication of the records. Occasionally, you may encounter a database with duplicate records due to human errors, bugs, or unclean data.
So, PostgreSQL offers several built-in functions to find duplicate rows/records from a table. This post will explain the below-listed methods that assist the users in finding the duplicate rows from a PostgreSQL table:
- How to Find Duplicates Using COUNT() Function in Postgres?
- How to Find Duplicates Using ROW_NUMBER() in Postgres?
So, let’s begin!
How to Find Duplicates Using COUNT() Function in Postgres?
The built-in functions always bring ease for the users, and so does the COUNT() function. In Postgres, the COUNT() function counts the number of rows/records. It assists the users in finding duplicate records in a specific table.
Example: How to Find Duplicates Using COUNT() Function?
In this example, we will present a step-by-step procedure to find duplicate records from a table:
Step #1: Create New Table
We will create a table named std_info using the CREATE TABLE as follows:
CREATE TABLE std_info( std_id INT, std_name TEXT, std_age INT);
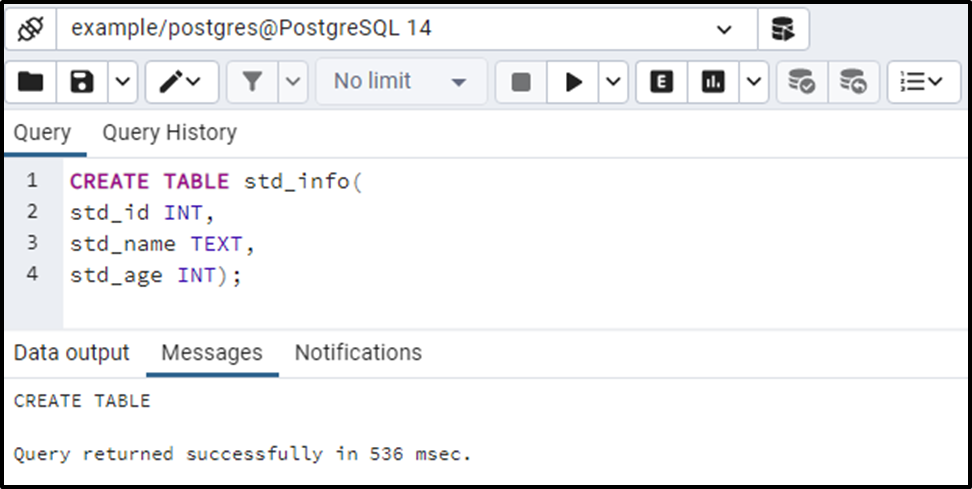
The output verifies that the std_info table with three columns has been created successfully.
Step #2: Insert Data Into Table
Now we will utilize the INSERT INTO statement to insert the data into the std_info table:
INSERT INTO std_info(std_id, std_name, std_age) VALUES (1, 'SETH', 18), (4, 'AMBROSE', 21), (3, 'JOHN', 17), (1, 'SETH', 18), (2, 'JOE', 19), (1, 'SETH', 18), (1, 'SETH', 18), (3, 'JOHN', 17), (1, 'SETH', 18), (3, 'JOHN', 17);
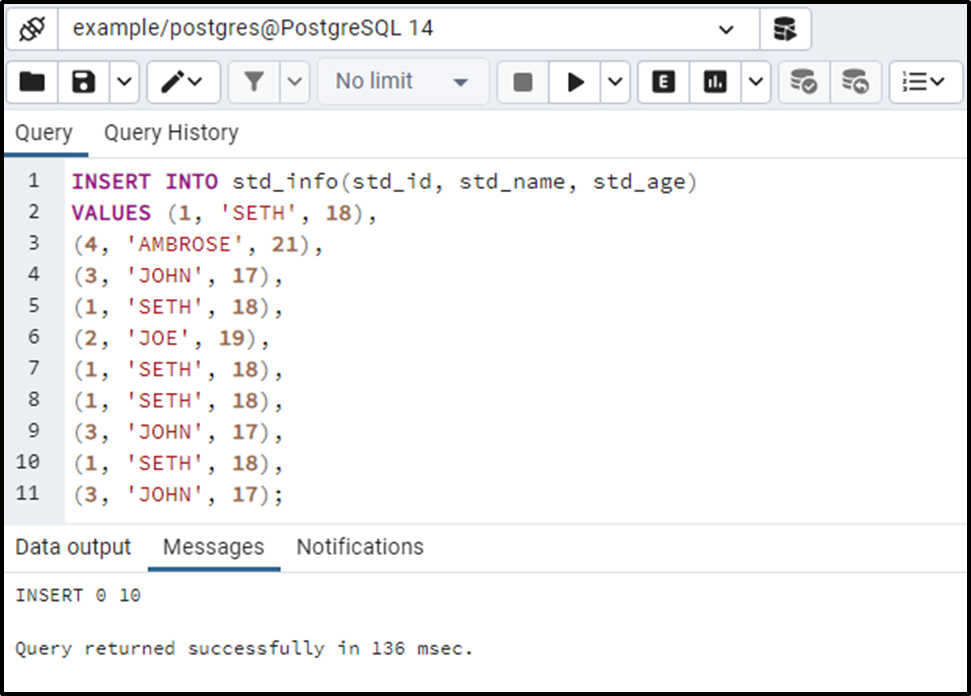
The output verifies that ten records have been inserted into the std_info table. From the output, it can be seen that some records are duplicated.
Step #3: Find Duplicates Using Count()
Let’s utilize the COUNT() function to find the duplicates from the std_info table:
SELECT std_name, COUNT(*) FROM std_info GROUP BY std_name HAVING COUNT(*) > 1;
In the above given query, we used the COUNT(*) function to count the number of rows. Next, we used the Postgres GROUP BY clause to group the rows/records based on std_name. Finally, we utilized the COUNT(*) function within the HAVING clause to find the duplicates:
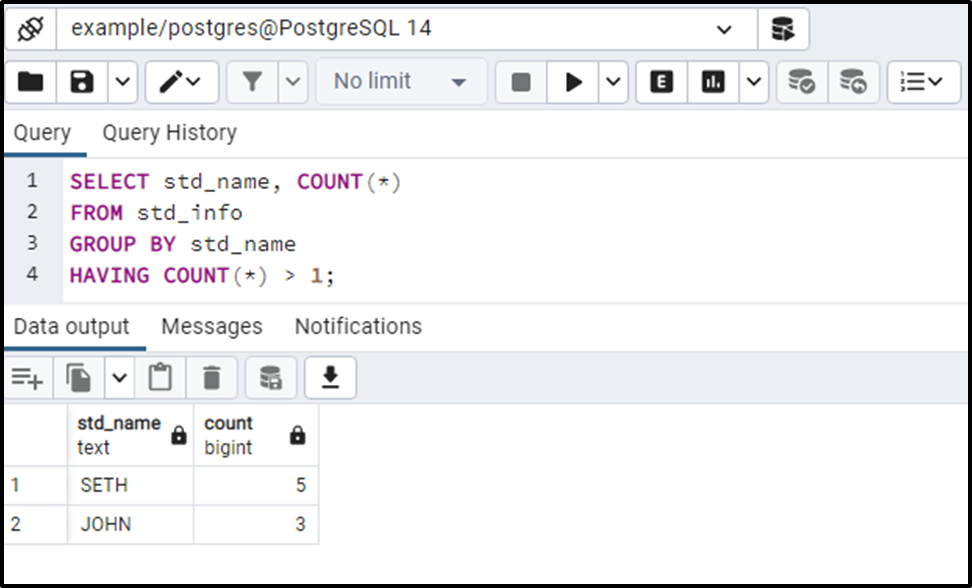
The output clarifies that the COUNT(*) function, with the aid of the HAVING clause, succeeded in finding the duplicate rows.
How to Find Duplicates Using ROW_NUMBER() in Postgres?
Another convenient way of finding duplicates is the ROW_NUMBER() approach. In PostgreSQL, the ROW_NUMBER() method can be used with the collaboration of the PARTITION BY Clause to find the duplicate rows from a table.
Example: How to Find Duplicates Using ROW_NUMBER() Method?
We will consider the same std_info table, and we will find the duplicate records from that table using the ROW NUMBER() method:
SELECT DISTINCT * FROM std_info WHERE std_name IN( SELECT std_name FROM(SELECT std_name, ROW_NUMBER() OVER(PARTITION BY std_name) AS occurrences FROM std_info) AS duplicates WHERE duplicates.occurrences > 1);
In the above query, we utilized the ROW_NUMBER() function to assign a sequential number to each record in the result set. Moreover, we utilized the PARTITION BY clause to make smaller sets/partitions. Finally, in the where clause, we specified a condition to find the duplicates(row >1):
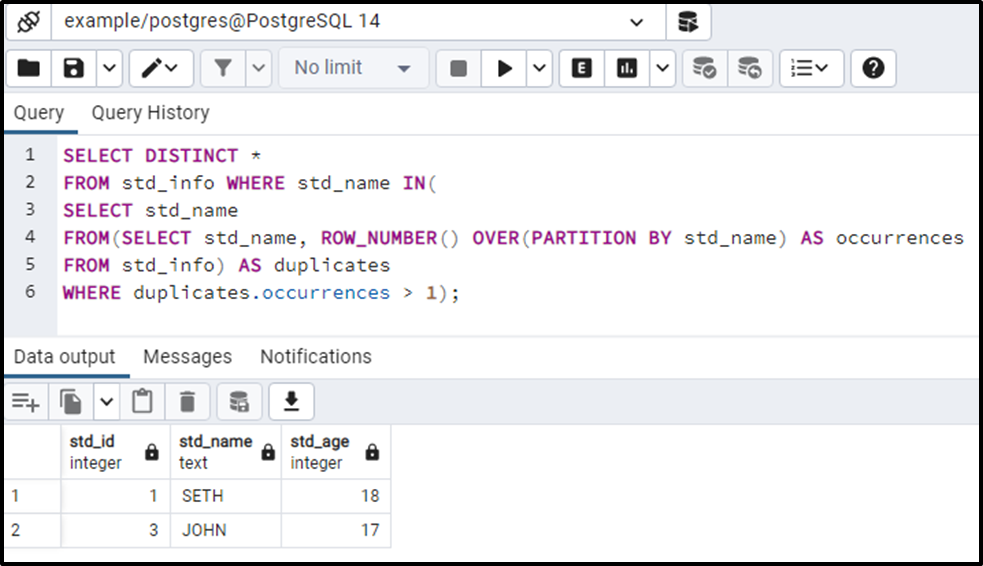
The output authenticates the working of the ROW_NUMBER() approach.
Conclusion
PostgreSQL offers several built-in functions to find duplicate rows/records from a table, such as ROW_NUMBER() and COUNT(). In Postgres, the COUNT() function counts the number of rows/records and can be used to find duplicate records in a specific table. While the ROW_NUMBER() method can be used with the collaboration of the PARTITION BY Clause to find the duplicate rows from a table. Using practical examples, this post explained how to find duplicates from the PostgreSQL table.


