
While working with databases, users may need to make a report that shows the very best or worst percentage of values from a set of data. For example, a user may want to calculate the top 1% of products with the highest or lowest revenue. For this purpose, Postgres offers a very convenient function named CUME_DIST() that can help us deal with such scenarios.
This write demonstrates how to use CUME_DIST Function in Postgres using the following outlines:
- Applying CUME_DIST() Function Over a Particular Table
- Applying CUME_DIST() Function Over a Table Partitions
How to Use CUME_DIST Function in PostgreSQL?
CUME_DIST() is one of the popularly used Window functions in Postgres that retrieves the cumulative distribution of a value for the given set of values.
Check the following syntax that will help you understand how to use CUME_DIST() function in Postgres:
CUME_DIST() OVER ( [PARTITION BY partition_col_list] [ORDER BY order_col_list] )
In the above syntax:
- "OVER" is a keyword that shows the starting point of the window function's operation. It tells the stated window function which rows to consider for its calculations.
- “[PARTITION BY partition_col_list]” is an optional clause that splits the result set into partitions based on columns specified in “partition_col_list”.
- Once the result set is divided into partitions, then the specified window function will be applied separately to each partition. However, if you omit this clause, the whole table/result set will be considered as a single partition.
- The ORDER BY is an optional clause that can be used within the CUME_DIST() function to arrange the rows within each partition.
- The stated function retrieves a double precision value in the following range: “0 < CUME_DIST() <= 1”
Let’s set up a sample table and practically implement the CUME_DIST() function on that table.
Sample Table
Let’s begin with creating a sample table named “transaction_details” that keeps the revenue details:
CREATE TABLE transaction_details( person_name TEXT NOT NULL, year SMALLINT CHECK (year > 0), transaction_amount DECIMAL(10,2) CHECK (transaction_amount >= 0), PRIMARY KEY (person_name, year) );
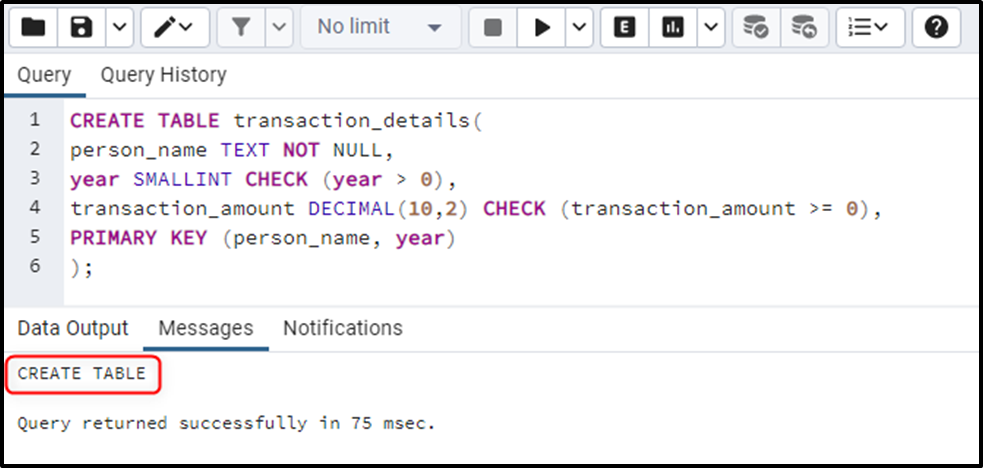
Once the desired table is created, insert some new records into it using the following query:
INSERT INTO transaction_details(person_name, year, transaction_amount)
VALUES ('Alexa', 2021, 150000),
('Joseph', 2020, 95000),
('Daniel', 2021, 135000),
('Anna', 2022, 125000),
('Stephan', 2023, 180000),
('Alex', 2021, 250000),
('Joe', 2021, 90000);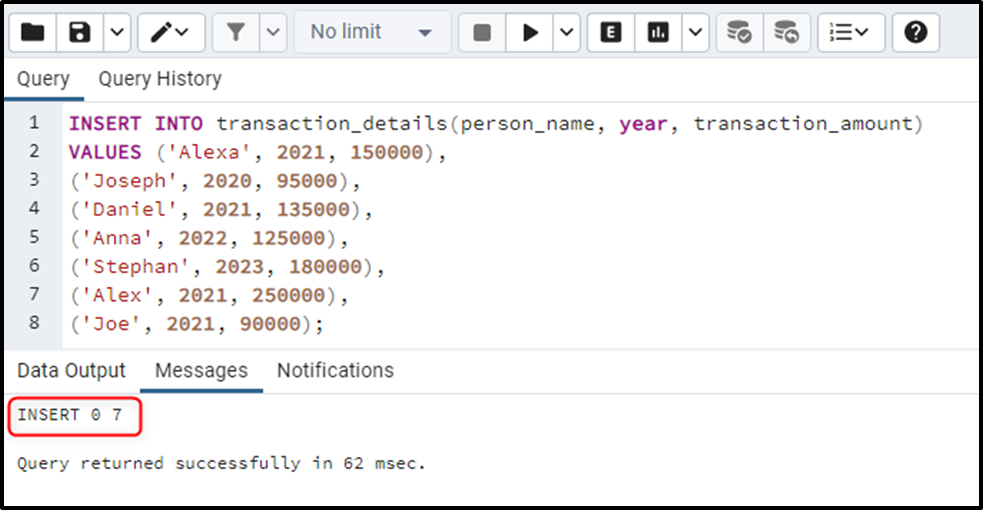
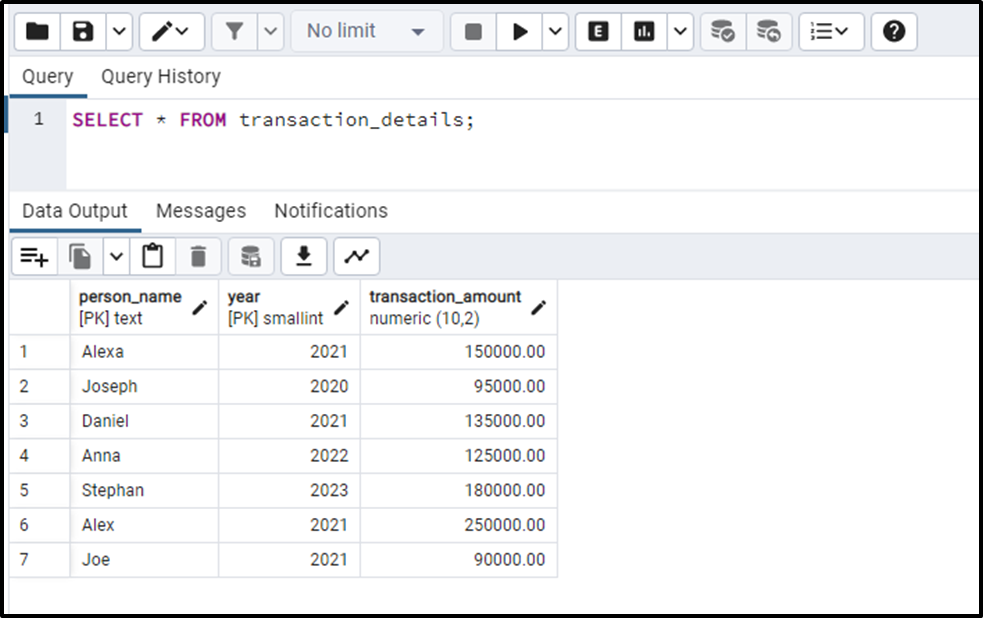
Let’s fetch the transaction_details table to confirm the inserted data:
SELECT * FROM transaction_details;
Example 1: Applying CUME_DIST() Function Over a Particular Table
In this example, we will apply the CUME_DIST() function on the “transaction_details” table:
SELECT person_name, year, transaction_amount, CUME_DIST() OVER ( ORDER BY transaction_amount ) FROM transaction_details WHERE year = 2021
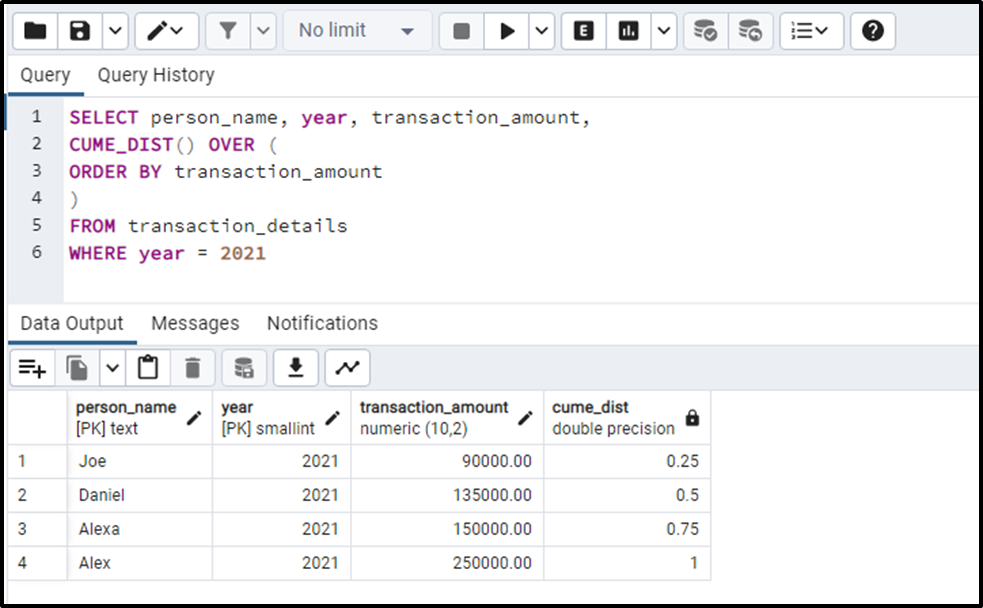
The output demonstrates that in the year 2021, the transaction amount of 75% of people was less than or equal to “150000”.
Example 2: Applying CUME_DIST() Function Over a Table Partition
In this example, we will apply the CUME_DIST() function on the table’s partition instead of the entire result set:
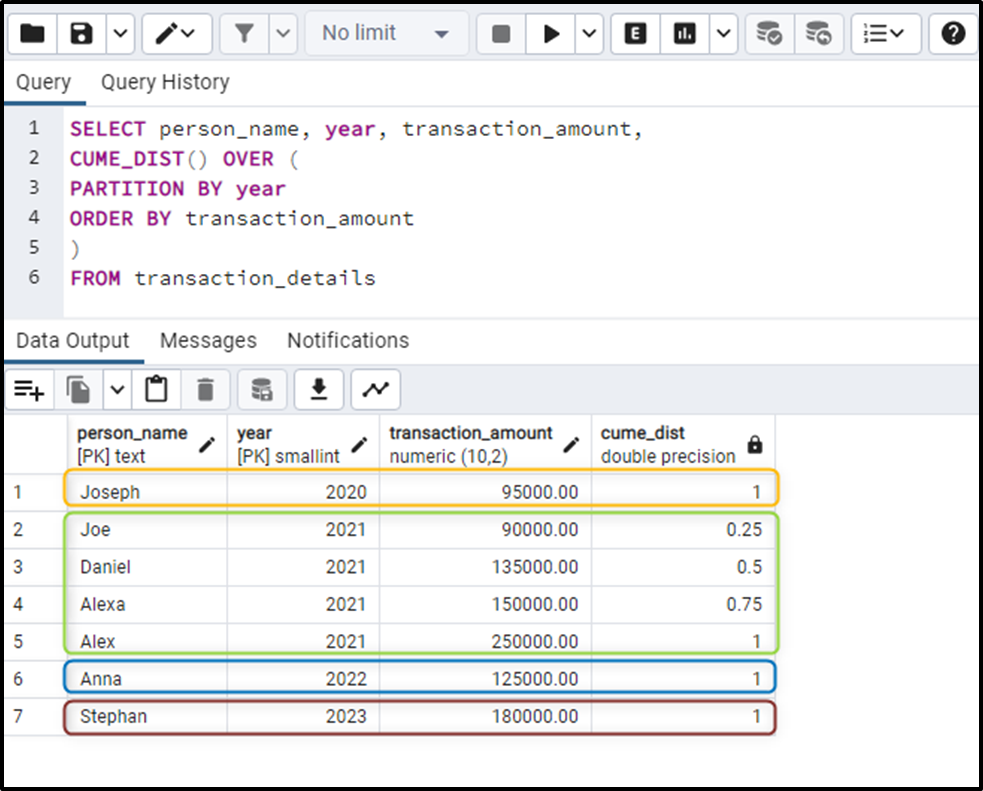
SELECT person_name, year, transaction_amount, CUME_DIST() OVER ( PARTITION BY DESC year ORDER BY transaction_amount ) FROM transaction_details
The output snippet depicts that the given result set has been divided into partitions (with respect to year), and the CUME_DIST() function has been successfully implemented over each partition:
That’s all about the CUME_DIST() function in Postgres.
Conclusion
In PostgreSQL, the CUME_DIST() function retrieves the cumulative distribution of a value for the given set of values. The PARTITION BY and ORDER BY clauses can be used with the CUME_DIST() function to split the result set into partitions and to sort the partition/result set, respectively. Moreover, the stated function can be applied over an entire result set or a specific partition depending upon the user's needs. This post has explained how to use the CUME_DIST() function in PostgreSQL.


