
A commonly used expression in Postgres is the DISTINCT expression. The DISTINCT clause is used to remove duplicate/same Postgres rows from the table. The DISTINCT ON clause works the same as the DISTINCT clause; the only difference is that the DISTINCT ON clause keeps the very first record of the duplicated records.
This write-up demonstrates the use of the DISTINCT ON expression in PostgreSQL.
How to Use DISTINCT ON Expression in Postgres?
We can discard all the identical/duplicate rows from a database table by making use of the DISTINCT and DISTINCT ON expressions. The DISTINCT operator removes the duplicated rows from a database record in addition to this the DISTINCT On keeps the first row/record and discards the duplicated ones. The basic syntax of the expression is:
SELECT DISTINCT ON col_1, col_2 FROM tab_name ORDER BY col_1, col_2;
In the above syntax:
● The columns in which we want to remove the duplicated records are specified after the DISTINCT ON keyword.
● The table’s name is written after the FROM keyword.
● The columns are ordered.
● We can also add some optional conditions in the query.
To get clarity on the concepts, let’s move towards an example.
Example: DISTINCT ON Expression in PostgreSQL
Let's create a table named “Students_marks” having data redundancy as the students attempted an online test multiple times:
CREATE TABLE Students_marks ( Student_id SERIAL PRIMARY KEY, Student_name VARCHAR(100) NOT NULL, Test_marks DOUBLE PRECISION NOT NULL );
Inserting the values in the table:
INSERT INTO Students_marks (student_name, Test_marks) VALUES
('Katherine', 7.25),
('Williams', 2.50),
('Alex', 5.00),
('John', 7.25),
('Smith', 2.50),
('Alex', 8.00),
('Smith', 8.50),
('Peter', 9.00),
('John', 7.25),
('Katherine', 9.50);The resultant table will be:
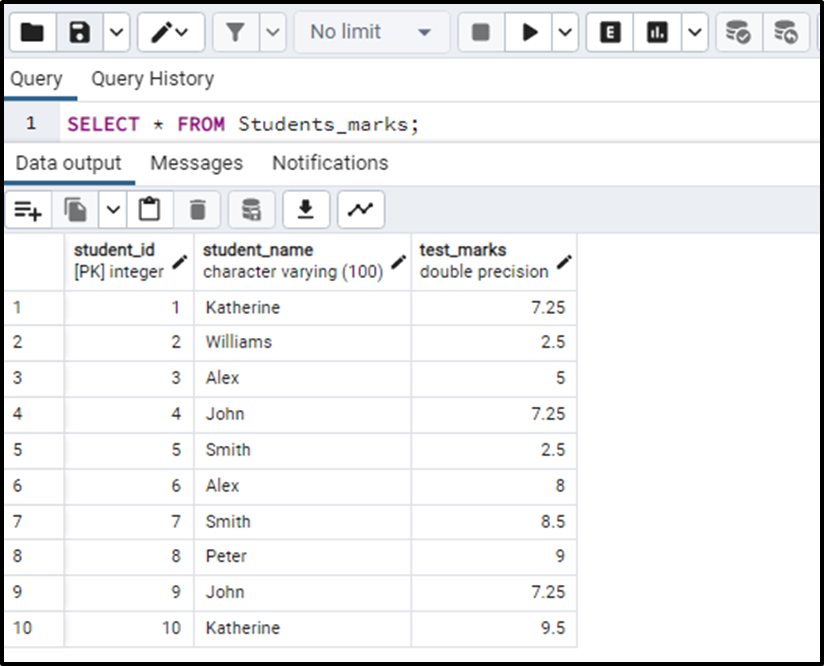
Now we can see that the names of the students are repeated multiple times. So in order to discard the redundant data and keep the marks of the students for their first attempt we will make use of the DISTINCT ON clause. The query for this use case will look like this:
SELECT DISTINCT ON (student_name)student_name, Test_marks FROM Students_marks ORDER BY student_name, Test_marks;
In the above code:
● We have used the DISTINCT ON expression to remove the redundant entries from the column ”student_name” of the table “students_marks”.
● We have ordered the data by the student_names and test_marks.
The query returns the table with the unique entities from the column “student_names” giving us the first records for each student in the table and the names of students ordered in alphabetical order. The output looks like this:
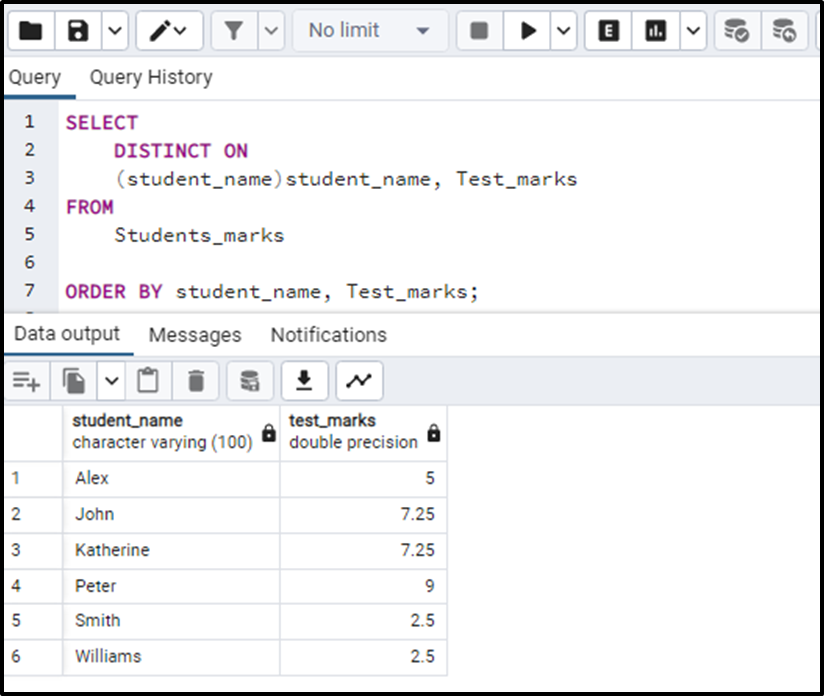
We can observe that the names of students are ordered in alphabetical order and the first attempt marks for every student are returned in the table.
This was all about the working of DISTINCT ON expression.
Conclusion
The DISTINCT ON clause works similarly to the DISTINCT clause as it returns the unique records of data after discarding the duplicate records. In addition to this, the DISTINCT ON expression returns the first record from the set of redundant data. In this article, we have learned about the DISTINCT ON expression in detail with the help of a practical example.


