
In PostgreSQL, the GROUP BY clause executes with the collaboration of a SELECT statement to group several items. It groups rows with identical or corresponding data returned by the SELECT statement. In most cases, it is employed to eliminate redundancy and calculate aggregates. You can use the GROUP BY clause with various functions like SUM() and COUNT() to perform different functionalities on the grouped items.
How to Use GROUP BY Clause in Postgres?
PostgreSQL users can specify an individual or multiple columns in the GROUP BY clause. As a result, the stated clause groups the rows based on the values in those specified columns.
The below figure demonstrates the evaluation precedence of the GROUP BY clause:
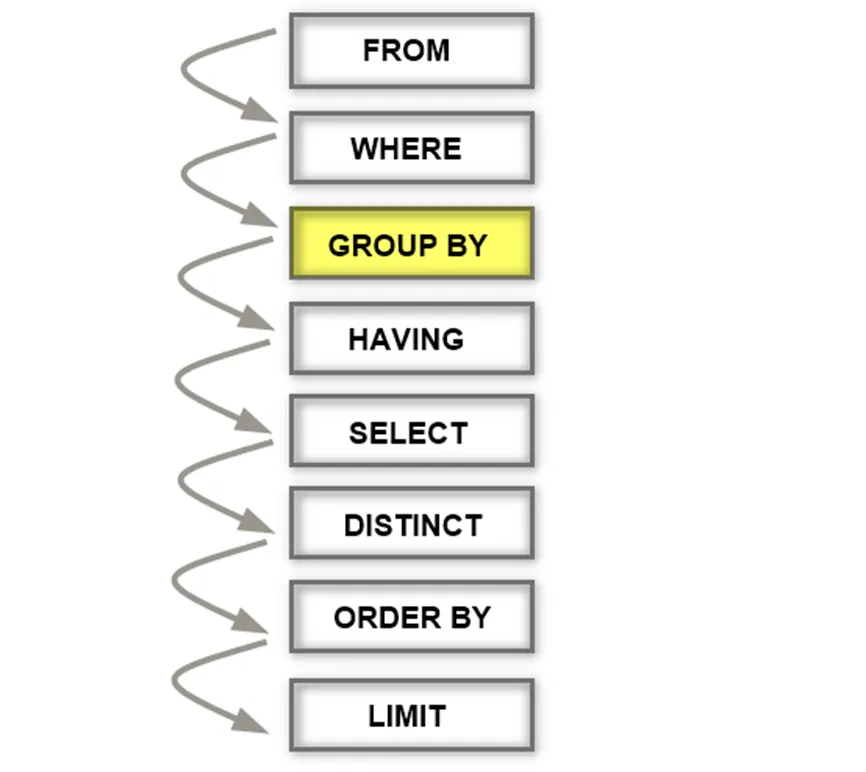
- The FROM clause and WHERE clause will come prior to the GROUP BY clause.
- The HAVING, DISTINCT, ORDER BY, and LIMIT clauses will come after the GROUP BY clause.
Syntax
Follow the comma-separated syntax to specify multiple columns within the GROUP BY clause:
SELECT list_of_columns FROM tab_name GROUP BY col_1, col_2....col_N
Let’s illustrate the above syntax step-by-step:
- Specify a column list in the SELECT statement that you want to group.
- Replace “tab_name” with the table name to which the selected columns belong.
- Replace the col_1, col_2, …, col_N with the columns to be grouped.
Let’s head into the practical implementation of the Postgres GROUP BY clause:
Example 1: A Basic Example of GROUP BY Clause
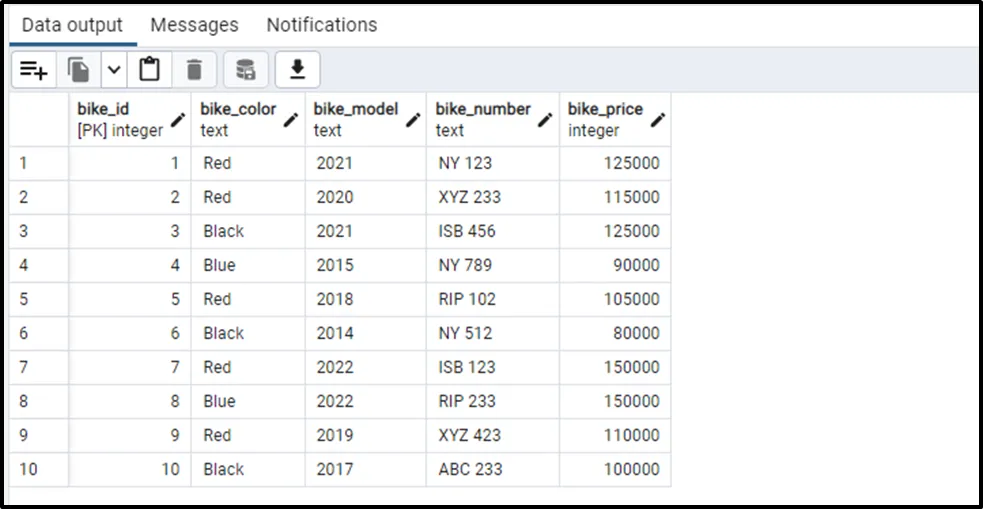
A table named "bike_details" has already been created that contains the following records:
Select * FROM bike_details;
The below-given query will get the record of the selected table, and it will group the result based on bike_model:
SELECT bike_model FROM bike_details GROUP BY bike_model;
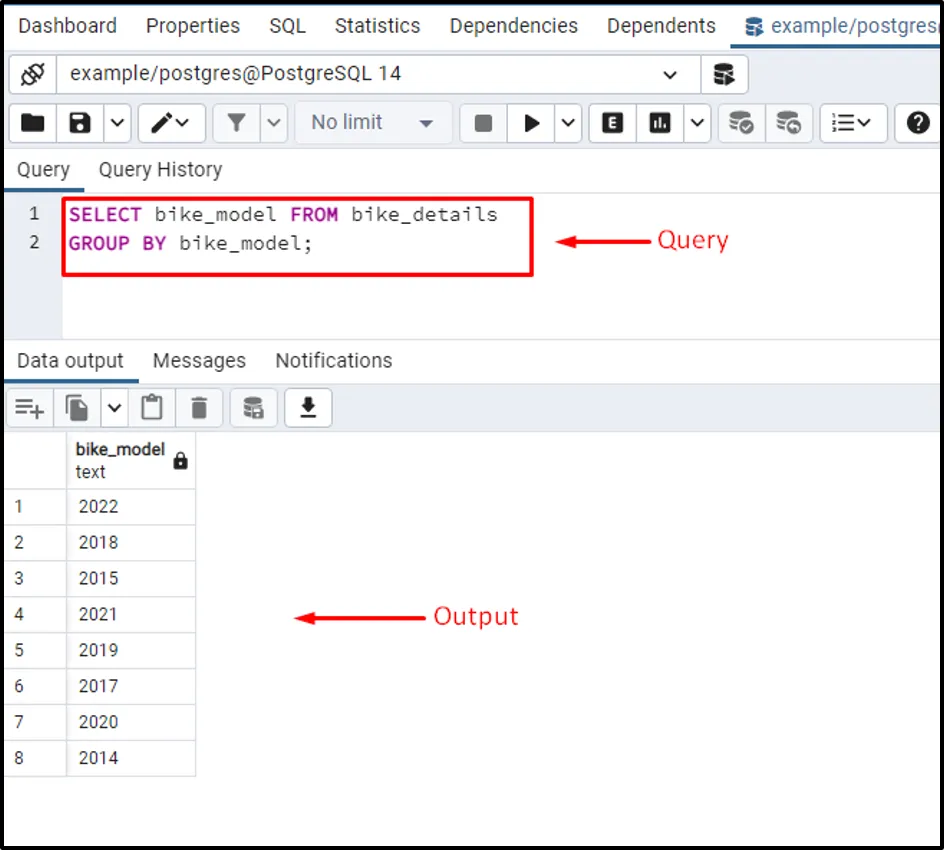
The output shows that the GROUP BY clause has eliminated the duplicated/redundant records.
Example 2: GROUP BY With ORDER BY
In Postgres, various clauses of the SELECT statement can be used with the GROUP BY clause, such as ORDER BY, WHERE, etc. In this example, we use the ORDER BY clause with the GROUP BY clause to sort and group the bike_model column in descending order:
SELECT bike_model FROM bike_details GROUP BY bike_model ORDER BY bike_model DESC;
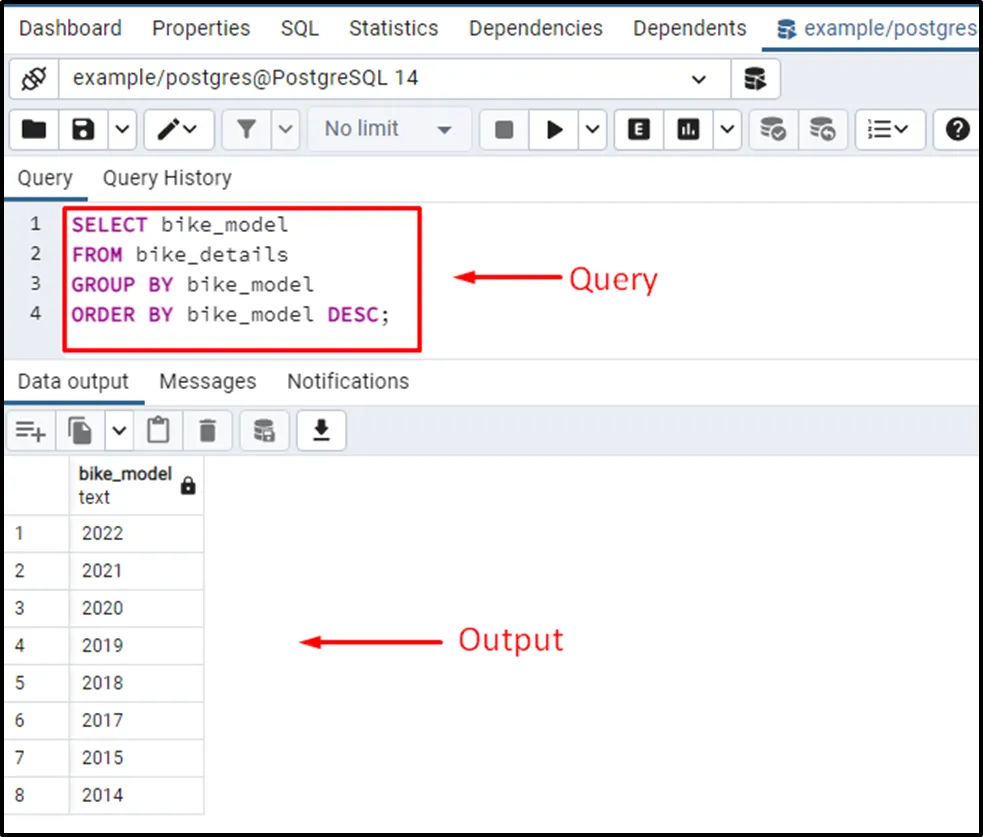
The output verified that this time the GROUP CLAUSE removed the redundant data and sorted the result-set in descending order.
How to Use GROUP BY With Aggregate Functions
Postgres users use the GROUP BY clause with the aggregate function to execute different tasks on the grouped data. Examples include calculating the sum or averages of group data.
Example 1: GROUP BY With SUM()
Let’s run the below-given query to find the sum of group items using the SUM() function:
SELECT bike_model, SUM (bike_price) FROM bike_details GROUP BY bike_model;
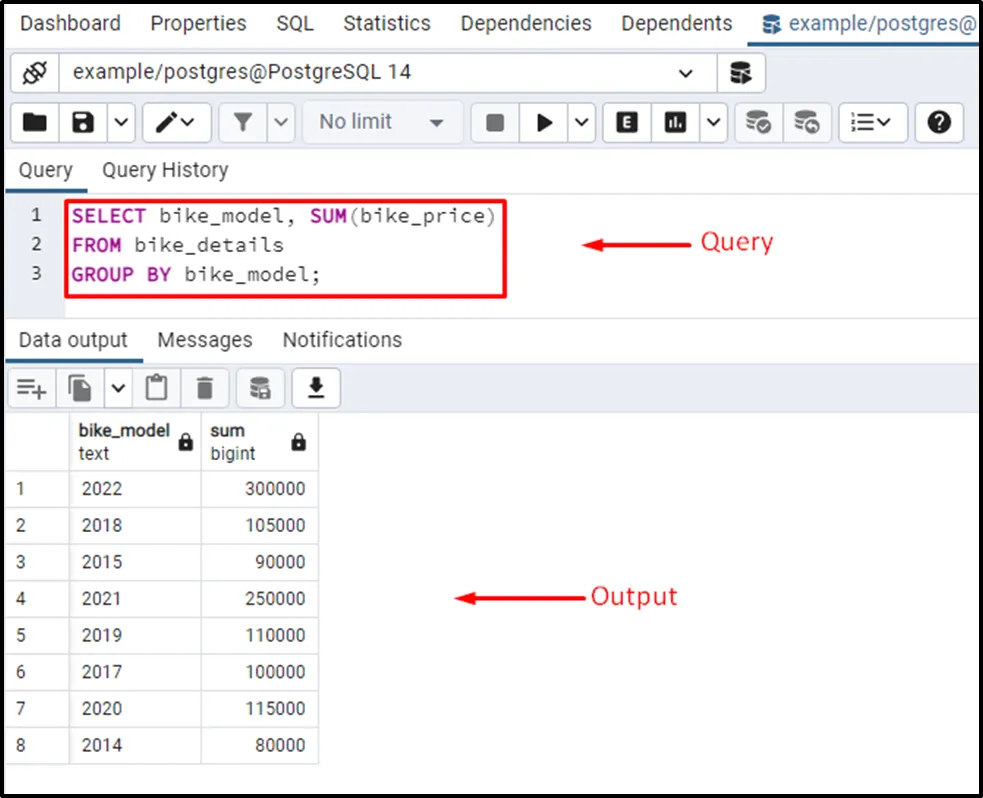
In this example, we utilized the GROUP BY clause to group the bikes with respect to their model. Next, we utilized an aggregate function named sum() that calculated the sum of group items.
Example 2: Postgres GROUP BY With COUNT()
In this example, we use the COUNT() function to count the number of bikes available for each model:
SELECT bike_model, COUNT (bike_model) FROM bike_details GROUP BY bike_model;
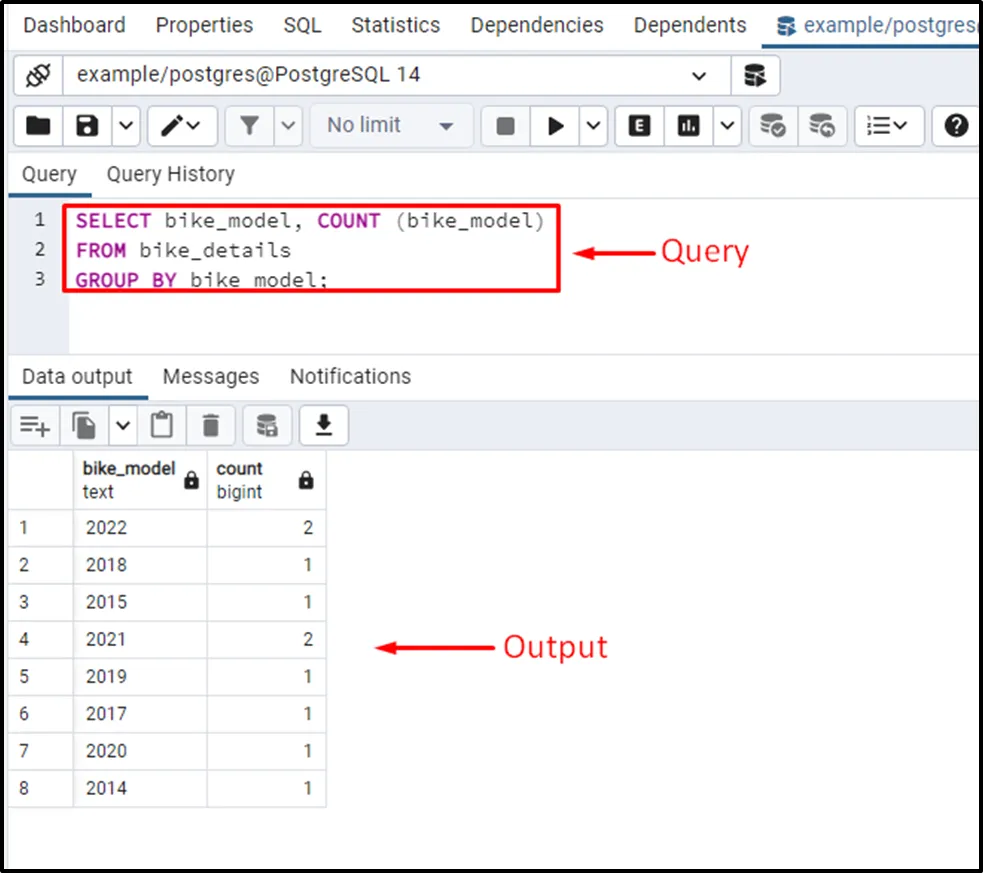
The output shows that in the result set, there are two bikes for the 2022 and 2021 models.
Example 3: Postgres GROUP BY With AVG()
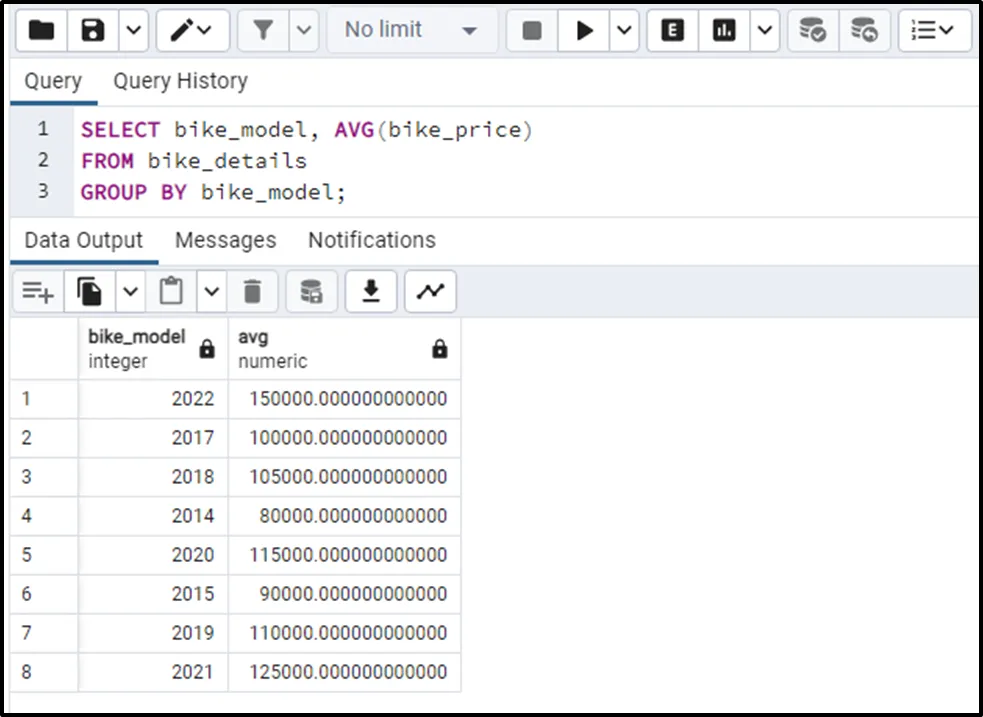
The following code uses the AVG() function to compute the average price of bikes based on their models:
SELECT bike_model, AVG(bike_price) FROM bike_details GROUP BY bike_model;
Example 4: Postgres GROUP BY With STRING_AGG()
Users often use the GROUP BY clause with the STRING_AGG() function to join values from multiple rows into a single string based on a specific grouping condition. Here is an example:
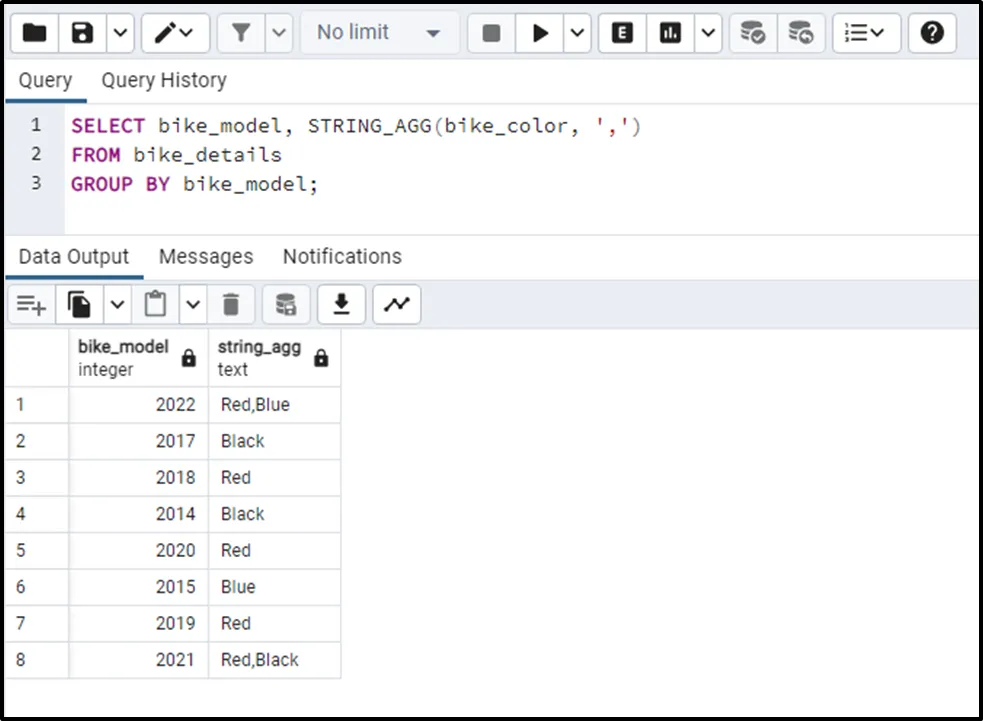
SELECT bike_model, STRING_AGG(bike_color, ',') FROM bike_details GROUP BY bike_model;
The stated query will show the available bike colors for each bike_model:
Example 5: Postgres GROUP BY With HAVING and an Aggregate Function
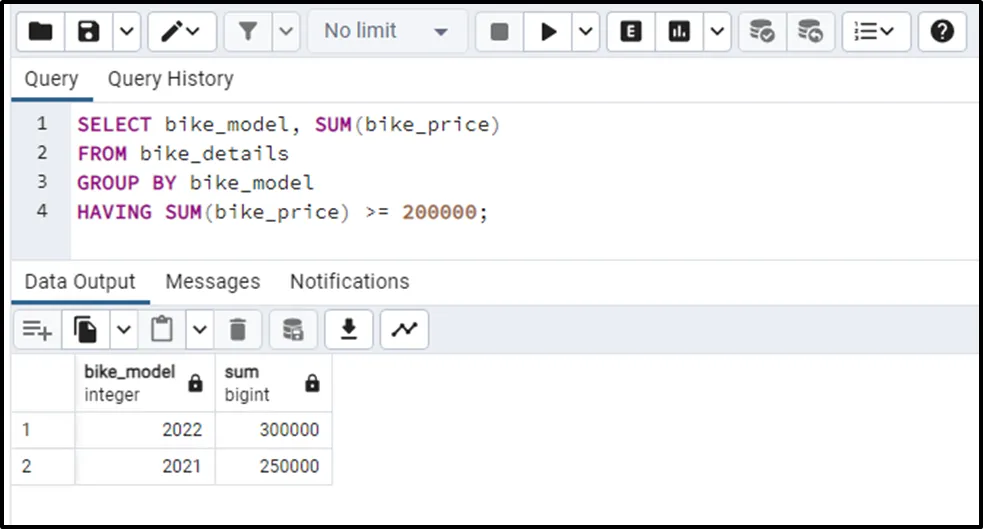
In the following code, we use the SUM() function, the HAVING clause along the GROUP BY clause to find those bikes whose group sum is more than 200000:
SELECT bike_model, SUM(bike_price) FROM bike_details GROUP BY bike_model HAVING SUM(bike_price) >= 200000;
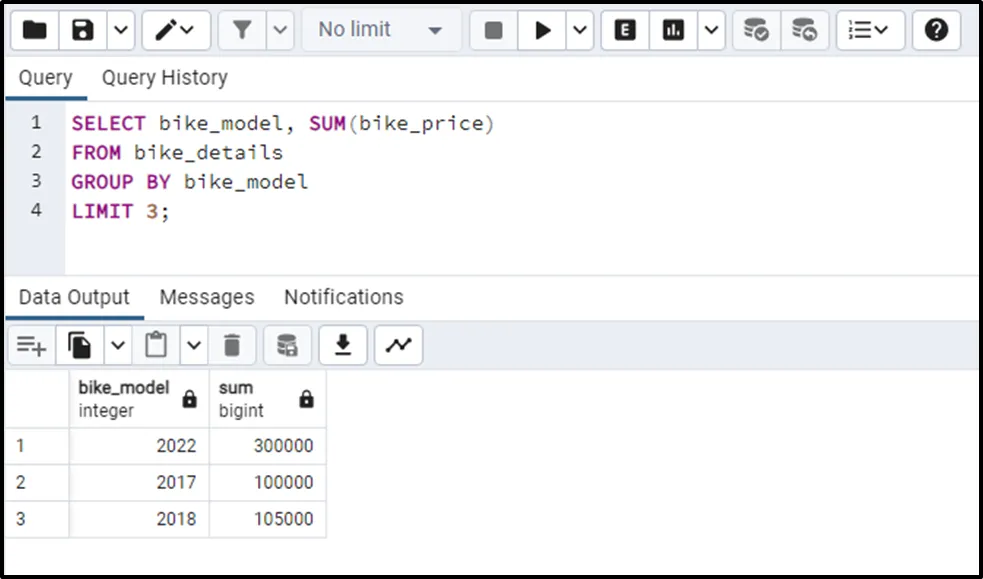
Example 6: Postgres GROUP BY With LIMIT and an Aggregate Function
The following code uses the GROUP BY With LIMIT clause and SUM() function to group the bikes based on their models and find the sum of only three bike_model:
SELECT bike_model, SUM(bike_price) FROM bike_details GROUP BY bike_model LIMIT 3;
That was all the basic information regarding the Postgres GROUP BY clause.
Conclusion
The GROUP BY clause in PostgreSQL is used with the collaboration of the SELECT statement to group several items. In this write-up, we have explained different use cases of the GROUP BY for various clauses, and aggregate functions. We have seen that the GROUP BY clause groups identical rows removes redundancy, and computes aggregates.


